LLM says buttons
The default interaction method used with contemporary Large Language Models (LLMs) is a text chat: user asks a question, LLM gives an answer. Inspired by Will Whitney’s post and conversations with Varun Godbole, I propose an alternative interface that could be implemented with current technology.
The commonly-used text interface is very expressive: the user can discuss topics from the latest car industry to finding the best place for a honeymoon. It also feels natural: it resembles the way humans talk to each other and every user has years of experience in using this form of communication.
While humans communicate effectively this way, there are many cases when talking to a machine is done more efficiently, e.g. - Drawing pictures in Photoshop - Creating spreadsheets for financial data - Writing code / this document: despite also using the text interface, the text editors have lots of useful features that makes editing drafts easier than prompting LLMs.
Two key UX challenges when using LLMs are:
- Discoverability: getting the user to understand what features/options exist and what they can use the tool for,
- Accessibility: allowing different users to adjust their experience based on their level of familiarity with a tool.
User-driven research
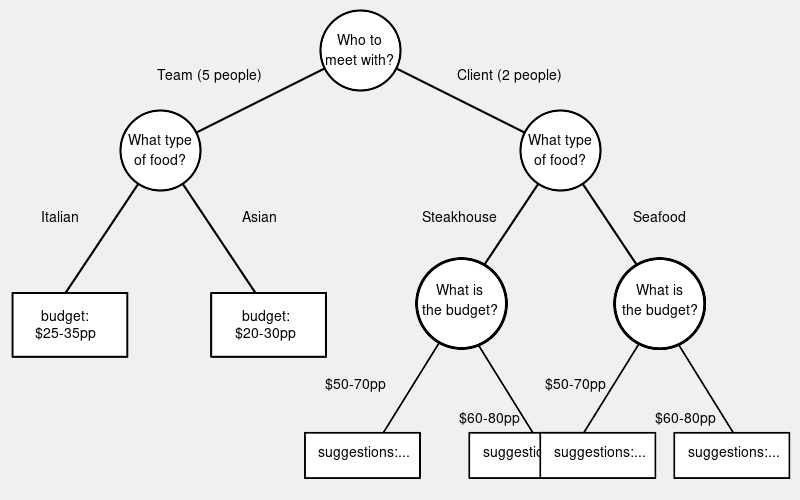
Researching a given idea involves scoping the problem right. For example, when trying to meet with others in a restaurant, one needs to decide:
- Who to meet with,
- When,
- What type of food,
- What type of budget should be involved.
When asked to help organize a restaurant visit, an LLM typically either makes assumptions about the user’s preferences (e.g., assuming they want lunch) or asks for clarification, leaving the decision to the user.
One can visualize the research process as a decision tree with nodes as the questions and edges as the potential answers:
Interface
Traversing this decision tree through lengthy responses interspersed with follow-up questions1 is both inefficient and unnatural.
Instead, the LLM can analyze whether it has enough information to answer the question. Until it does, it can iterate:
- asking itself about the next piece of information needed and the best widget to gather it (eg. a map for the location, slider for the price, button for cuisine type)
- show the widget to the user to get the answer
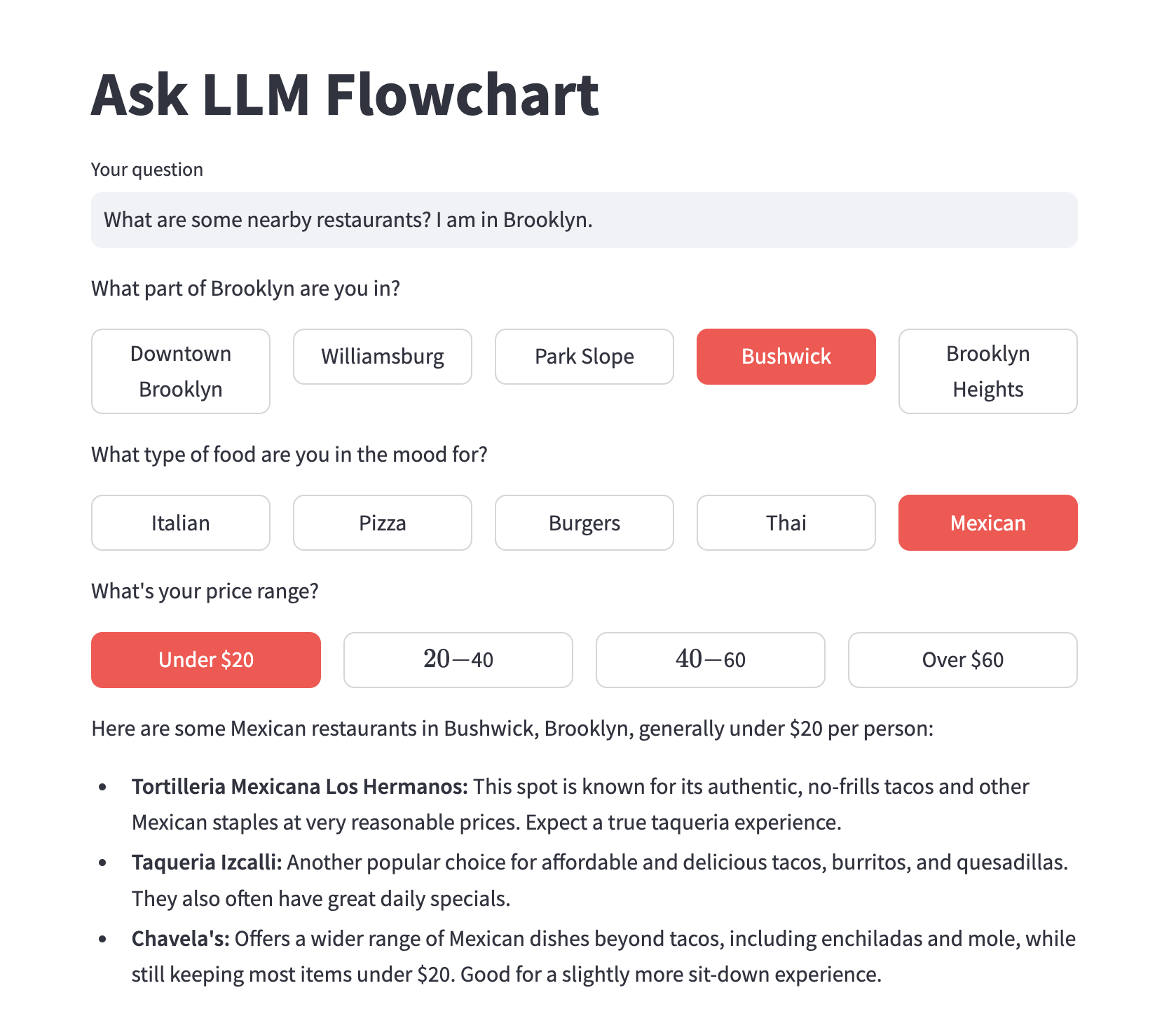
Update 17-01: You can try the prototype here.
Benefits
The balance between making assumptions and asking users questions is a difficult one to strike. On one hand, we want the LLM to provide as useful and accurate information as it can; on the other, repeatedly asking the user to clarify the request leads to fatigue and discourages users.
Making it easier for users to express preferences shifts the balance away from guessing, as pressing buttons three times is less cognitively demanding than reading multiple responses and composing text replies.
Furthermore, expressing the first question/prompt in natural language is not, paradoxically, the most natural way of starting a conversation for humans2.
Users’ behavior with Google’s search engine demonstrates this remark: even though it can handle natural language well these days, most of
us3 only put keywords, like python type self, as they express the intention clearly enough in most of the cases.
A structured conversation makes it easier for users to backtrack on their answers and investigate a different continuation: now, if the user wants to provide a different answer to some of the clarifying questions, she only needs to press a different button.
Storing memories
Driving the conversations in a more structured way will likely lead to the very same widget being displayed multiple times to the same user over the course of their lifes: we go to get food many times over and decide how to do so every time.
Being able to retrieve the history of user’s answers to the particular question allows the LLM to skip asking it altogether (like it does now), while taking the user’s preferences into account.
Even better, one can envision an entropy-based model, where the uncertainty of the user’s answer is modeled and the question is re-asked in intervals that are propotional to the confidence level of the model, letting user to change their preferences every now and then.
Concerns
This idea faces two challenges:
First, “LLM says buttons” interface requires multiple model calls, what is more expensive than the traditional chat interaction. The cost of sampling is proportional to the number of input and output tokens4. Given that the clarifying discussion happens at the beginning of the conversation, the extra input to handle would be relatively small: apart from the KV-cached user prompt, it would be just a couple of sentences to the LLM asking for clarification question and widget.
Second, button interface increase latency in two ways:
- Users must complete all widget interactions before receiving results
- Each generation of a button requires a new model inference.
While the first one is hard to eliminate, the second one could be handled by having a smaller (and thus: faster) network, potentially served closer to the user (as it’s cheaper to run), whose only goal would be generation of the UI elements.
Outro
While text-based chat remains the foundation of LLM interfaces, introducing structured elements like buttons could bridge the gap between natural conversation and efficient tool usage. This hybrid approach might just be the key to making AI assistants both more powerful and more accessible to everyone.
In the example conversation, Claude shows recommendations for a couple of different areas and then proceeds to ask about cuisine and budget.↩︎
Not to mention the unnatural prompting techniques that encourage the LLM to answer like: “You are a senior expert…”↩︎
a reference to the polite grandma story is required here↩︎
with different coefficients↩︎